

































New to KubeDB? Please start here.
Overview
Hazelcast is an open-source, Java-based, information retrieval library with support for limited relational, graph, statistical, data analysis or storage related use cases. Hazelcast is designed to drive powerful document retrieval or analytical applications involving unstructured data, semi-structured data or a mix of unstructured and structured data. Hazelcast is highly reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. Hazelcast powers the search and navigation features of many of the world’s largest internet sites.
Supported Hazelcast Features
| Features | Availability |
|---|---|
| Clustering | ✓ |
| Customized Docker Image | ✓ |
| Authentication & Autorization | ✓ |
| Reconfigurable Health Checker | ✓ |
| Custom Configuration | ✓ |
| Grafana Dashboards | ✓ |
| Externally manageable Auth Secret | ✓ |
| Persistent Volume | ✓ |
| Monitoring with Prometheus & Grafana | ✓ |
| Builtin Prometheus Discovery | ✓ |
| Alert Dashboard | ✓ |
| Using Prometheus operator | ✓ |
| Automated Version Update | ✓ |
| Automatic Vertical Scaling | ✓ |
| Automated Horizontal Scaling | ✓ |
| Automated Volume Expansion | ✓ |
| Autoscaling (vertically, volume) | ✓ |
| TLS: Add, Remove, Update, Rotate ( Cert Manager ) | ✓ |
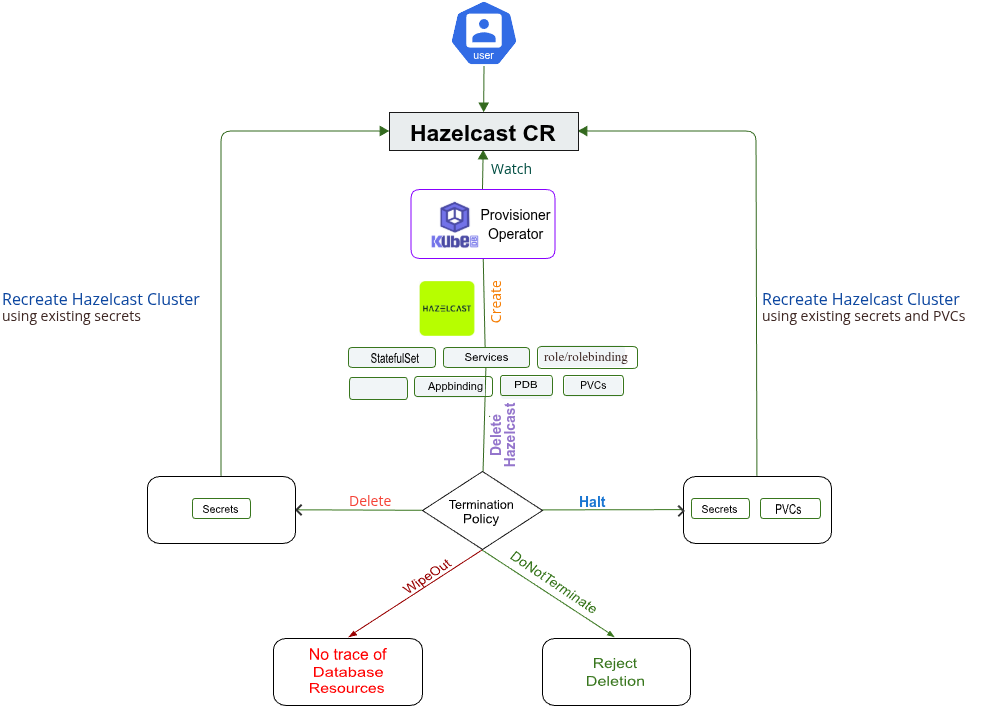
Life Cycle of a Hazelcast Object
User Guide
- Quickstart Hazelcast with KubeDB Operator.
- Detail Concept of Hazelcast Object.
Next Steps
- Want to hack on KubeDB? Check our contribution guidelines.